productcrawlercrawlers
How AI Crawlers Actually See Your Website: A Technical Introduction for E-Commerce Marketers
Your product pages may be perfectly optimized for Google—and completely invisible to ChatGPT, Perplexity, and Claude. This guide breaks down exactly how AI crawlers work, why they differ from Googlebot, and what e-commerce marketers can do right now to fix their AI search visibility.
15 min readRecently updated

are preserved" ]
# How AI Crawlers Actually See Your Website: A Technical Introduction for E-Commerce Marketers
*Product pages may be perfectly optimized for Google—and completely invisible to ChatGPT, Perplexity, and Claude. This guide breaks down exactly how AI crawlers work, why they differ from Googlebot, and what e-commerce marketers can do right now to fix their AI search visibility.*
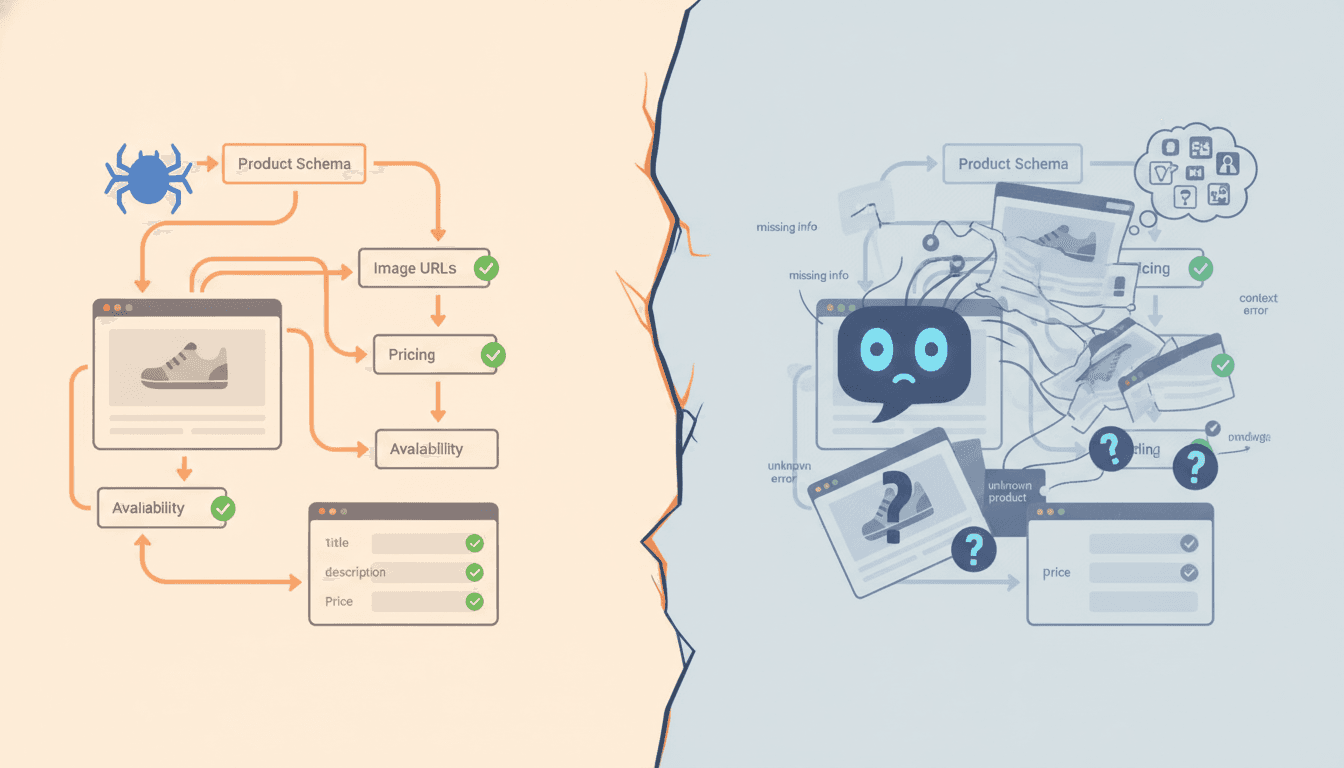
[IMG: Split-screen visualization showing a modern e-commerce product page as rendered in a browser vs. the sparse raw HTML that an AI crawler receives—emphasizing the visibility gap]
An uncomfortable truth confronts e-commerce operators today: while 26% of U.S. adults now use AI chatbots to research purchases, most product pages remain invisible to them. ChatGPT, Perplexity, and Claude cannot see prices, descriptions, or inventory status on the majority of e-commerce sites.
The culprit isn't intentional blocking. It's a fundamental technical mismatch between how different crawlers operate. Unlike Googlebot, which renders JavaScript like a full browser, AI crawlers like GPTBot, ClaudeBot, and PerplexityBot read only raw HTML. Client-side rendered product pages, dynamic pricing, and JavaScript-powered pagination are completely invisible to these systems.
The scale of this problem is significant. Research shows that 85% of e-commerce sites have at least one critical technical issue preventing AI crawlers from seeing their product content. This guide reveals exactly what AI crawlers see when they visit a site—and provides a practical framework to fix it.
---
## The Fundamental Technical Divide: Why Googlebot and GPTBot Are Not the Same
Googlebot operates more like a browser than a traditional web crawler. It uses a [Chromium-based rendering engine](https://developers.google.com/search/docs/crawling-indexing/javascript/javascript-seo-basics) to execute JavaScript, wait for dynamic content to load, and index the fully rendered page—a process that takes an average of 2–5 seconds per JavaScript-heavy page. Google even built a two-wave indexing system specifically to account for this rendering delay, separating initial HTML crawling from later JavaScript rendering.
AI crawlers operate nothing like that.
GPTBot, ClaudeBot, and PerplexityBot function as simple HTTP clients: they send a GET request, receive the initial HTML response, and move on—near-instantaneously. There is no second wave, no JavaScript execution, and no rendering queue. What's in the raw HTML is all these systems ever see.
The commercial implications are severe. Research from [Botify and Lumar](https://www.lumar.io) found that 63% of product detail pages on JavaScript-heavy e-commerce sites return an empty or near-empty HTML body to non-rendering crawlers. Titles, descriptions, prices, and specifications built with React, Vue, or Angular—without server-side rendering—simply do not exist for AI systems.
Lily Ray, VP of SEO Strategy & Research at Amsive Digital, frames the challenge clearly: *"The challenge with AI crawlers is that they're essentially reading websites the way a browser did in 2005—they see the raw HTML, and if content isn't in that initial server response, it simply doesn't exist for them. Most modern e-commerce sites have inadvertently made themselves invisible to AI systems without realizing it."*
This visibility gap is fixable. An AI visibility audit identifies exactly what GPTBot, ClaudeBot, and PerplexityBot see on product pages—and provides a prioritized roadmap to address it. Hexagon's technical SEO team specializes in helping e-commerce brands assess their AI crawler visibility and develop custom remediation strategies. [Book a 30-minute consultation](https://calendly.com/ramon-joinhexagon/30min) to discuss a tailored approach.
---
## The AI Crawler Ecosystem: Understanding GPTBot, ClaudeBot, PerplexityBot, and Beyond
The AI crawler landscape has exploded in complexity. As of 2025, e-commerce operators may need to account for [over 30 distinct AI crawler user-agent strings](https://darkvisitors.com) in their robots.txt and server configurations—compared to fewer than five major crawlers that dominated the landscape in 2020. Each crawler has different crawl frequency, robots.txt behavior, and content usage policies.
Here are the major players e-commerce marketers need to know:
- **GPTBot** (OpenAI) — Launched publicly in August 2023; feeds ChatGPT training and browsing features; does not execute JavaScript
- **ClaudeBot / Claude-Web** (Anthropic) — Gathers training data and enables real-time web retrieval for Claude; standard HTTP client without JavaScript rendering
- **PerplexityBot** (Perplexity AI) — Retrieves real-time web content for cited answers; respects robots.txt; no JavaScript execution
- **Google-Extended** — Introduced September 2023; allows opt-out from Gemini AI training without blocking standard Googlebot indexing
- **Amazonbot** — Amazon's crawler for Alexa and AI product features
- **Meta-ExternalAgent** — Meta's crawler for AI training and product features
- **Apple-Bot** — Apple's crawler for Siri and AI-powered features
Understanding crawler purpose is equally important. A critical distinction exists between **training crawlers** and **retrieval crawlers**. Training crawlers like GPTBot's training mode operate in large periodic sweeps to build AI model datasets. Retrieval crawlers like PerplexityBot need fresh, frequently re-crawled content to generate real-time answers.
E-commerce sites need to satisfy both categories to appear in AI-generated product recommendations. For example, a product that appears in training data but isn't regularly re-crawled won't show up in real-time AI search results.
[IMG: Ecosystem diagram mapping major AI crawlers by company, use case (training vs. retrieval), and JavaScript rendering capability]
Martin Splitt, Developer Advocate at Google Search, frames the divide clearly: *"AI training and retrieval crawlers are optimizing for scale and cost—rendering JavaScript at the scale they need to crawl would require enormous compute resources. The practical result is that server-side rendering has gone from an SEO best practice to a business-critical requirement for AI visibility."*
---
## The robots.txt AI Blocking Crisis: How Legacy Rules Are Locking Out AI Crawlers
Nearly half of major e-commerce sites are accidentally blocking AI crawlers. A [2024 crawl analysis](https://originality.ai) of top e-commerce domains found that **46% of the top 1,000 e-commerce websites** have robots.txt rules blocking at least one major AI crawler—GPTBot, ClaudeBot, or PerplexityBot. The majority of this blocking is unintentional.
The primary culprit is legacy wildcard disallow rules written before AI crawlers existed. Common problematic patterns include:
- `Disallow: /` paired with specific Googlebot allowances—a pre-2023 SEO pattern that blocks every crawler except those explicitly permitted
- `Disallow: /*` wildcard rules intended for old scraper bots that now catch all modern AI crawlers
- Blanket `User-agent: *` blocks with no exceptions for AI crawler user-agents that post-date the configuration
These patterns often linger for years, invisible to site operators who never revisit their robots.txt configuration.
Gary Illyes, Analyst at Google Search, captures the protocol's core limitation: *"Robots.txt was never designed for a world where one might want to allow one type of AI crawler but not another, or allow retrieval but not training. E-commerce operators who want nuanced control over their AI visibility need to understand that they're essentially managing a growing list of named exceptions—and that list is expanding every quarter."*
A robots.txt audit should be the first step in any AI visibility remediation effort. Many site operators are entirely unaware that AI crawler blocking is happening—and that competitors may already be capitalizing on the gap.
---
## Client-Side vs. Server-Side Rendering: Why React Product Pages Disappear
Client-side rendering is the silent killer of AI crawler visibility. When a product page built with React, Vue, or Angular without server-side rendering (SSR) is requested by GPTBot, the crawler receives a nearly empty HTML shell—a `<div id="root"></div>` and a JavaScript bundle reference. The actual product title, description, price, and specifications never appear in the response.
[IMG: Code comparison showing a CSR product page's raw HTML response (empty shell) vs. an SSR product page's raw HTML response (full product content visible)]
Server-side rendering or static pre-rendering solves this problem by ensuring complete product content is present in the initial HTML response—before any JavaScript executes. The [63% figure from Botify and Lumar](https://www.lumar.io) makes the scale of this problem concrete: the majority of product detail pages on JavaScript-heavy sites are effectively invisible to AI systems.
Platform defaults matter significantly. Different e-commerce platforms ship with different baseline rendering approaches:
- **Shopify** — Product content typically server-side rendered by default via Liquid templates; third-party app-injected content (reviews, dynamic pricing) is often client-side rendered and invisible
- **WooCommerce** — Theme-dependent; many popular themes use client-side rendering for key product elements
- **Magento / Adobe Commerce** — Enterprise configurations often use API-first architecture requiring careful SSR setup
- **Headless / Custom React builds** — Require explicit SSR or static generation (Next.js, Nuxt.js) to expose any product content to AI crawlers
Aleyda Solis, International SEO Consultant at Orainti, identifies the common thread among AI-visible sites: *"The sites winning in AI-generated product recommendations share a common technical profile: server-side rendered HTML with complete product data in the initial response, comprehensive Schema.org Product markup, clean URL structures without session parameters, and explicit robots.txt permissions for major AI crawlers."*
---
## Structured Data as Your AI Crawler Lifeline: Why Schema.org Markup Matters More Than Ever
When AI crawlers cannot execute JavaScript, structured data becomes their primary window into product identity. [Schema.org markup](https://schema.org/Product) embedded in server-delivered HTML provides machine-readable signals for product name, pricing, availability, and reviews—signals that AI systems would otherwise have to infer from unstructured text, often unreliably.
The essential Schema.org markup types for e-commerce AI visibility include:
- **Product** — Core product identity, name, description, brand, SKU
- **Offer** — Pricing, availability, currency, seller information
- **AggregateRating** — Overall review score and review count
- **Review** — Individual customer review content
Critically, this structured data must be present in the **initial HTML response**—not injected via JavaScript after page load. JSON-LD format is preferred precisely because it can be embedded directly in the server response, making it reliably readable by non-rendering crawlers. Sites that inject structured data dynamically via JavaScript lose the benefit entirely when AI crawlers are involved.
The scale of this gap is significant. The [Screaming Frog / SEMrush E-Commerce Technical Audit Benchmark Report](https://www.semrush.com) found that 85% of e-commerce sites have at least one critical AI-visibility issue—and missing or JavaScript-injected structured data is among the most common findings. For sites already struggling with client-side rendering, structured data is often the last remaining lifeline for AI crawler comprehension.
---
## The Pagination and Catalog Depth Problem: Why AI Crawlers Only See Page One
For large e-commerce catalogs, the rendering gap creates a depth problem that compounds invisibility. AI crawlers process only the initially returned HTML document—which means infinite scroll and JavaScript-powered pagination create a "page one only" visibility problem that can leave thousands of products completely undiscovered.
Here's how common catalog patterns fail AI crawlers:
- **Infinite scroll** — AI crawlers see only the products in the initial HTML load; scroll-triggered product loading never fires
- **JavaScript-powered pagination** — If pagination links aren't present in the initial HTML, there is no crawl path to deeper catalog pages
- **Faceted navigation and dynamic filtering** — URL parameters and filter states generated by JavaScript are invisible, meaning filtered product subsets cannot be crawled
Static XML sitemaps with individual product URLs provide a partial workaround—they give AI crawlers direct URLs to product pages, bypassing category navigation entirely. However, sitemaps alone don't guarantee deep catalog visibility if the product pages themselves have rendering issues.
Server-side pagination with traditional HTML `<a>` links remains the most AI-crawler-friendly approach for category and search results pages. For example, a category page with numbered pagination buttons in the HTML is fully crawlable, while one relying on JavaScript to load the next page is not.
---
## Platform-Specific Vulnerabilities: Shopify, Magento, WooCommerce, and Headless Builds
Understanding platform defaults helps e-commerce teams prioritize their remediation efforts. Different platforms carry different baseline AI crawler accessibility profiles—and the gap between best and worst case is substantial.
**Shopify** offers the most favorable default profile. Standard Liquid-template storefronts render product content server-side, making core product data accessible to AI crawlers. The vulnerability lies in third-party apps: review widgets, dynamic pricing tools, upsell modules, and personalization layers are typically client-side rendered, creating partial product profiles in AI systems.
**WooCommerce** visibility depends heavily on theme and plugin architecture. Many popular WooCommerce themes use client-side rendering for product galleries, pricing, and variation selectors. Plugin-injected content—especially reviews and dynamic inventory—frequently bypasses server-side rendering entirely.
**Magento / Adobe Commerce** enterprise configurations often use API-first architecture, where product data is fetched client-side via GraphQL or REST calls. Without careful SSR configuration, this approach creates significant AI crawler blind spots for pricing, inventory, and product attributes.
**Headless and custom React builds** represent the highest-risk category. Shopify Hydrogen, BigCommerce Catalyst, and custom Next.js storefronts require explicit server-side rendering or static site generation (SSG) configuration for every content type that needs AI crawler visibility. Without intentional SSR setup, all product content—descriptions, reviews, pricing, inventory status—is invisible.
[IMG: Platform comparison matrix showing Shopify, WooCommerce, Magento, and headless builds rated across AI crawler accessibility dimensions: default SSR, structured data support, robots.txt defaults, and pagination approach]
---
## Practical AI Crawler Audit Checklist: Step-by-Step Technical Assessment
Here's how to assess a site's AI crawler visibility systematically, without specialized tools.
**Step 1: Audit robots.txt**
- Navigate to `yourdomain.com/robots.txt`
- Check for `User-agent: *` rules with broad `Disallow: /` or `Disallow: /*` patterns
- Search specifically for named blocks of `GPTBot`, `ClaudeBot`, `PerplexityBot`, `Google-Extended`, and `Amazonbot`
- Verify that any AI crawler blocks are intentional, not legacy artifacts
**Step 2: Run a curl test on product pages**
- Use `curl -A "GPTBot" https://yourdomain.com/products/your-product` to simulate what AI crawlers receive
- Compare the curl output to what appears in a browser—significant differences indicate client-side rendering issues
- Look specifically for product title, price, description, and structured data in the curl response
**Step 3: Validate structured data**
- Use [Google's Rich Results Test](https://search.google.com/test/rich-results) and the [Schema.org validator](https://validator.schema.org) on key product pages
- Confirm that Product, Offer, AggregateRating, and Review markup is present and valid
- Verify structured data appears in the page source (not injected via JavaScript)
**Step 4: Check server response headers**
- Review `Content-Type`, `Cache-Control`, `X-Robots-Tag`, and `Content-Security-Policy` headers
- `X-Robots-Tag: noindex` in HTTP headers can block AI crawlers even when robots.txt is clean
**Step 5: Review crawl logs**
- If using Google Search Console, analyze Googlebot crawl behavior as a proxy for overall crawler accessibility
- Third-party log analysis tools can identify GPTBot and PerplexityBot access patterns directly
**Step 6: Compare AI crawler view vs. user view**
- Use browser DevTools Network tab to see fully rendered content
- Compare against curl output to quantify the visibility gap on the most important product pages
---
## The Commercial Reality: Why AI Crawler Visibility Matters Now
The consumer behavior data makes the business case impossible to ignore. [Pew Research Center and eMarketer data](https://www.pewresearch.org) shows that **26% of U.S. adults** who used an AI chatbot in the past month used it to research a product or service purchase—up from under 10% in 2022. That growth trajectory represents a fundamental shift in how consumers discover products.
Looking ahead, AI-powered product discovery is on track to become a mainstream purchase research channel within two to three years. Brands that remain invisible to AI crawlers today are already losing discoverability to technically optimized competitors. The compounding effect matters: AI training data is collected now, and the brands that establish AI crawler visibility early will appear in AI-generated recommendations as these systems mature.
Early movers in AI visibility optimization are building a durable competitive advantage. The technical barriers are real but solvable—and the window for first-mover advantage is still open.
---
## Action Plan: Fixing AI Crawler Visibility Today
Remediation doesn't require rebuilding an entire e-commerce stack. The path forward is sequenced by effort and impact.
**Immediate actions (days):**
- Audit and fix robots.txt to remove unintentional AI crawler blocks
- Run curl tests on top 20 product pages to identify rendering gaps
- Validate existing structured data and fix critical errors
**Short-term fixes (1–2 weeks):**
- Add or correct Schema.org Product, Offer, AggregateRating, and Review markup on all product pages
- Ensure structured data is server-rendered, not JavaScript-injected
- Submit updated XML sitemaps with complete product URL coverage
**Medium-term improvements (2–8 weeks):**
- Implement SSR or static pre-rendering for critical product pages on client-side rendered platforms
- Replace JavaScript-powered pagination with server-side HTML pagination on category pages
- Audit and fix third-party app content that renders client-side on Shopify or WooCommerce
**Long-term strategy:**
- Redesign e-commerce architecture with AI crawler visibility as a core technical requirement alongside traditional SEO
- Establish ongoing monitoring: set up alerts for robots.txt changes, structured data errors, and crawl anomalies
- Use tools like [Screaming Frog](https://www.screamingfrog.co.uk), Google Search Console, and third-party AI crawler simulators for continuous validation
The competitive window is open now. Brands that act on AI crawler visibility today will compound that advantage as AI-powered product discovery continues its rapid growth. The technical work is straightforward, the ROI is clear, and the first-mover advantage is real.
---
Not sure if a site has these issues? An AI visibility audit identifies exactly what GPTBot, ClaudeBot, and PerplexityBot see on product pages—and provides a prioritized roadmap to fix it. Hexagon's technical SEO team specializes in helping e-commerce brands assess their AI crawler visibility and develop custom remediation strategies. [Book a 30-minute consultation](https://calendly.com/ramon-joinhexagon/30min) to discuss a tailored approach.H
Hexagon Team
Published June 19, 2026