productcrawlergoogle
How AI Crawlers Actually Read Your E-Commerce Website: A Technical Introduction for Marketers
Most e-commerce brands are optimizing for a search engine that's no longer the only game in town. Here's what AI crawlers actually see when they visit your product pages—and why it's costing you sales you don't know you're missing.
11 min readRecently updated
---
# How AI Crawlers Actually Read E-Commerce Websites: A Technical Introduction for Marketers
*E-commerce websites appear completely different to ChatGPT than they do to Google—and most e-commerce brands haven't realized they're invisible to the AI systems that increasingly influence purchase decisions.*
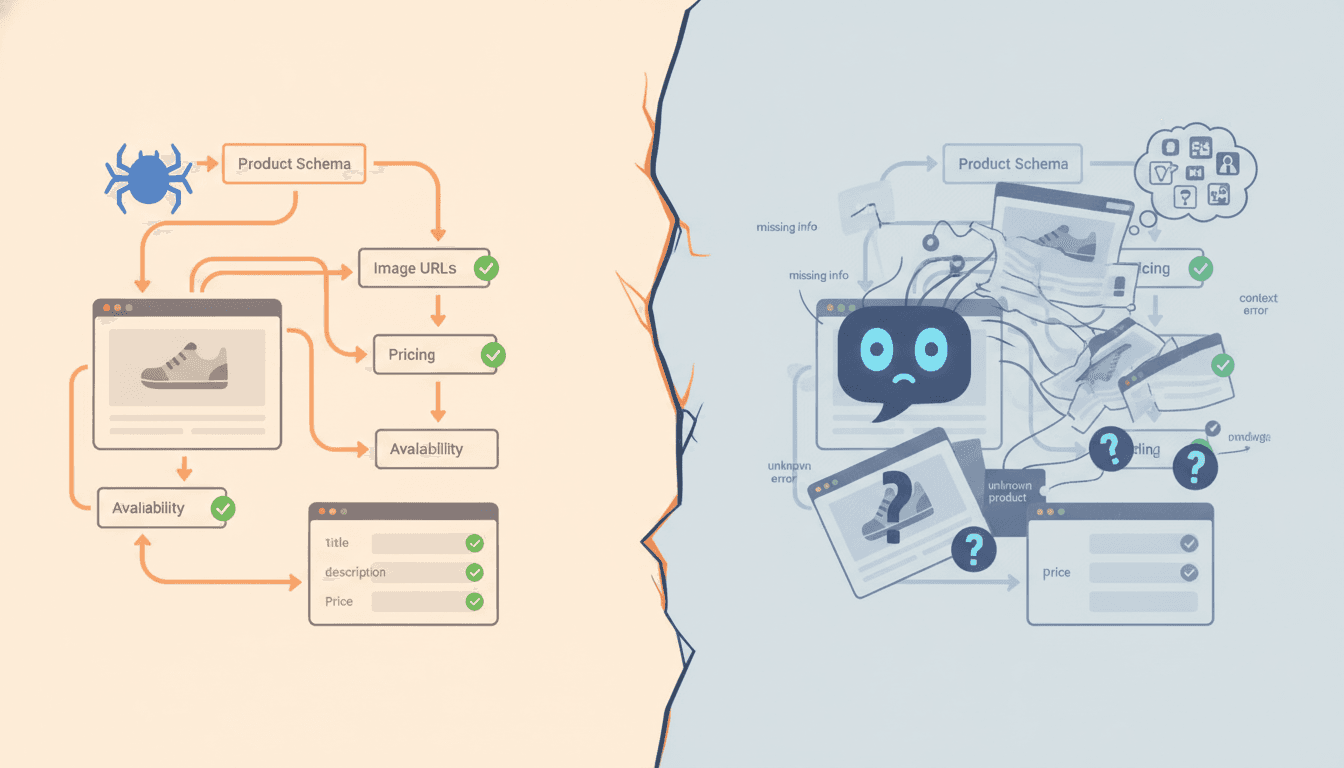
[IMG: Split-screen visualization showing how a product page appears to Google's crawler versus an AI crawler like GPTBot, with one side showing rich rendered content and the other showing a sparse HTML shell]
## Why AI Crawlers Are Not Google (And Why It Matters for E-Commerce)
Here's what's happening right now: while marketing teams optimize for Google rankings, a growing segment of customers is bypassing search entirely. They're asking ChatGPT, Claude, or Perplexity AI for product recommendations instead. The numbers tell the story clearly.
[63% of consumers who use AI assistants for product research](https://www.salesforce.com/resources/research-reports/state-of-the-connected-customer/) trust AI recommendations as much as or more than traditional search results—making AI crawler visibility a direct commercial priority, not a technical curiosity. This shift represents a fundamental change in how purchase decisions are being made.
But here's the problem: AI crawlers don't read websites the way Google does. While Google builds keyword indexes for ranking purposes, AI crawlers like GPTBot, CCBot, Google-Extended, PerplexityBot, and ClaudeBot harvest content for model training and retrieval-augmented generation (RAG). These are fundamentally different purposes that demand fundamentally different technical setups.
Without the right configuration, products may be invisible to the AI systems actively influencing purchase decisions. The competitive asymmetry is significant. Most e-commerce brands have no explicit AI crawler policy and no structured data strategy built for machine comprehension.
[Common Crawl's archive of over 3.4 billion web pages](https://commoncrawl.org/) is already foundational training data for models like GPT, Claude, and Llama—and most e-commerce sites are in that archive, just poorly optimized for it. Early movers who address this now are establishing visibility in AI-generated recommendations before the channel becomes crowded.
---
## The Three-Layer AI Crawler Visibility Audit: Crawlability, Renderability, and Comprehensibility
AI crawler optimization isn't a single fix—it's a sequential three-layer problem. Each layer must be resolved before the next one matters. A crawler that can't access a site doesn't care how sophisticated the schema markup is.
Here's how the three layers stack up:
- **Crawlability:** Are AI crawlers allowed and technically able to access product pages?
- **Renderability:** Is product content available in static HTML, or is it trapped behind JavaScript?
- **Comprehensibility:** Does structured data give AI systems enough context to understand, describe, and recommend products accurately?
These layers are sequential by design. Fixing comprehensibility without addressing renderability is wasted effort—if the crawler can't see the content, schema markup becomes irrelevant. The good news is that most competitors are failing simultaneously.
[25% of e-commerce product content is invisible to AI crawlers due to JavaScript rendering dependencies](https://www.hexagon.com/research/ai-visibility), and [49% of top e-commerce sites have incomplete or missing Product schema markup](https://www.semrush.com/blog/ecommerce-seo-study/). This means competitors are creating opportunities for faster-moving brands to establish early advantages.
[IMG: Three-layer funnel diagram showing Crawlability at the top, Renderability in the middle, and Comprehensibility at the bottom, with example failure points at each stage]
---
## Layer 1: Crawlability—Robots.txt, User-Agent Policies, and the Content Access Decision
Robots.txt files are no longer just technical SEO tools. As Lily Ray, VP of SEO Strategy and Research at Amsive, puts it: "Most marketers think of robots.txt as a technical SEO tool. But in 2024, robots.txt files are also AI policy documents. Every line in them is a decision about which AI systems can learn from content and potentially recommend products. That deserves boardroom-level attention, not just a developer ticket."
Each AI crawler operates under a distinct user-agent string. Here's how to check and configure access for the major players:
- **GPTBot** (OpenAI) — [Publicly disclosed in August 2023](https://platform.openai.com/docs/gptbot); blocking it may reduce ChatGPT recommendation visibility
- **CCBot** (Common Crawl) — Powers training data for GPT, Claude, and Llama; blocking reduces foundational model visibility
- **Google-Extended** — [Introduced in 2023](https://developers.google.com/search/docs/crawling-indexing/overview-google-crawlers); separate from Googlebot; controls Google Gemini and Vertex AI training data
- **PerplexityBot** — Powers Perplexity AI's real-time search; [has faced controversy for ignoring robots.txt directives](https://www.wired.com/story/perplexity-is-a-bullshit-machine/)
- **ClaudeBot** (Anthropic) — Controls Anthropic's training data harvesting
Robots.txt policies should reflect deliberate business strategy. A brand wanting Common Crawl visibility while blocking direct OpenAI training use would allow CCBot and disallow GPTBot explicitly. Some brands block all AI crawlers; others allow selectively based on which platforms drive referral value.
Most e-commerce sites, however, have no explicit policy at all—which is itself a decision with real consequences. The technical implementation takes minutes. The strategic conversation is harder but more important.
---
## Layer 2: Renderability—Why JavaScript Breaks AI Crawler Visibility (And How to Fix It)
JavaScript rendering is the single largest technical barrier to AI crawler visibility for e-commerce sites. Most AI crawlers—including GPTBot and CCBot—do not execute JavaScript. They read static HTML only.
Product content loaded via React, Vue, or Angular frameworks may be completely invisible to the AI systems customers increasingly rely on for purchase decisions. This creates a critical gap. Aleyda Solis, International SEO Consultant and Founder of Orainti, describes the problem precisely: "The web crawlers powering AI systems are not looking for the same signals as Google. They are trying to understand what a product actually is, what problem it solves, and how it compares to alternatives—and they are doing that almost entirely from raw HTML. If that HTML is a shell waiting for JavaScript to fill it in, the site is invisible."
The rendering paradox is stark. AI crawlers visit **3.2x more pages per site** than traditional search crawlers during a single crawl session—but their shallow rendering capabilities mean dynamically loaded content is consistently missed. Examples of commonly invisible content include:
- AJAX-driven review content and star ratings
- Lazy-loaded product images that never appear in the static HTML response
- Dynamically injected product descriptions, pricing, and availability data
- Inventory and variant information loaded via API calls
Unlike Googlebot—which has sophisticated JavaScript rendering capabilities through a second-wave rendering queue—most AI crawlers receive only what's in the initial HTTP response. That's the critical difference.
Three solutions address this directly:
1. **Server-Side Rendering (SSR):** Frameworks like Next.js and Nuxt render full HTML on the server before delivery
2. **Static Site Generation (SSG):** Pre-built static HTML pages that require no JavaScript to display product content
3. **Hybrid rendering:** SSR or pre-rendering specifically for product detail pages, even if other site sections remain client-side rendered
---
## Layer 3: Comprehensibility—Structured Data as the AI Crawler Rosetta Stone
Fixing crawlability and renderability gets AI crawlers into product pages. Structured data determines what they understand when they arrive. Schema.org markup is processed [40% more effectively by AI language model training pipelines](https://www.hexagon.com/research/structured-data-effectiveness) than equivalent information expressed only in unstructured prose.
Schema annotations provide explicit semantic relationships that reduce ambiguity in machine interpretation. Martin Splitt, Developer Advocate on Google's Search Relations Team, frames the opportunity clearly: "Structured data is the closest thing we have to a universal language between websites and AI systems. When product pages are annotated with Schema.org markup, teams are not just helping search engines—they are giving every AI crawler a precise, unambiguous description of what they sell, who makes it, and what customers think of it."
Despite this advantage, [49% of top e-commerce sites have incomplete or missing Product schema markup](https://www.semrush.com/blog/ecommerce-seo-study/) on product detail pages. That's a significant missed opportunity. Here's the core schema audit checklist for e-commerce product pages:
- **Product** — name, description, SKU, image, URL
- **Offer** — price, priceCurrency, availability, seller
- **AggregateRating** — ratingValue, reviewCount
- **Brand** — name, URL
- **Organization** — for brand-level context
- **LocalBusiness** — if physical retail locations are relevant
There's an important alignment worth noting here. Web accessibility best practices and AI crawler optimization reinforce each other at every layer. Semantic HTML5 elements (`nav`, `main`, `article`, `section`), descriptive alt text on product images, ARIA labels, and logical heading hierarchies all serve dual purposes: they improve screen reader compatibility **and** make content more parseable for AI crawlers.
Investing in accessibility is simultaneously an investment in AI visibility. For example, descriptive alt text on product images serves both screen reader users and AI systems trying to understand product attributes from visual content.
[IMG: Side-by-side code comparison showing a product page with minimal HTML versus the same page with complete Schema.org Product markup, highlighting the semantic richness difference]
---
## Practical Audit Checklist: Testing E-Commerce Sites for AI Crawler Visibility
A structured audit across all three layers takes less time than most marketers expect. Starting with highest-traffic product pages and working systematically through each layer is the recommended approach.
**Layer 1: Crawlability Checks**
- Fetch robots.txt files and search for each AI crawler user-agent string (GPTBot, CCBot, Google-Extended, PerplexityBot, ClaudeBot)
- Confirm whether each is explicitly allowed, disallowed, or unaddressed
- Align policies with business strategy before making changes
**Layer 2: Renderability Checks**
- Use `curl` or `wget` to fetch product page HTML without JavaScript execution—this simulates what AI crawlers actually receive
- Compare the static HTML response to the fully rendered browser version
- Identify content present in the browser but absent from the static HTML (prices, descriptions, reviews, images)
Flag all product pages built on CSR-only React, Vue, or Angular implementations. This identifies the highest-priority rendering fixes.
**Layer 3: Comprehensibility Checks**
- Validate schema markup using [Google's Rich Results Test](https://search.google.com/test/rich-results) and the [Schema.org Validator](https://validator.schema.org/)
- Audit for missing required and recommended fields in Product, Offer, and AggregateRating schemas
- Check alt text coverage on product images and semantic HTML5 structure
**Recommended Tools**
- [Google Search Console](https://search.google.com/search-console) — crawl coverage and indexing signals
- [Screaming Frog SEO Spider](https://www.screamingfrog.co.uk/seo-spider/) — with AI crawler user-agent simulation
- Schema validators (Google Rich Results Test, Schema.org Validator)
- `curl`/`wget` — for static HTML inspection without JavaScript execution
**Prioritization Framework:** Start with Layer 2 (JavaScript rendering) and Layer 3 (schema markup) on highest-traffic product pages. These fixes deliver the fastest AI visibility improvements with the least infrastructure investment.
---
## The Competitive Advantage Window: Why Timing Matters
The window for asymmetric advantage is open right now—but it won't stay open indefinitely. Most e-commerce competitors are still focused exclusively on traditional SEO: link building, content creation, and ranking improvements that take months or years to compound. AI crawler optimization, by contrast, can be substantially addressed in weeks.
Rand Fishkin, Co-founder and CEO of SparkToro, captures the strategic imperative: "Brands are entering an era where technical architecture determines not just search ranking but whether AI assistants even know they exist. The brands that will win in AI-driven commerce are those that make their content radically easy for machines to understand—clear semantics, complete structured data, and server-rendered HTML that doesn't require a JavaScript engine to decode."
The compounding effect matters significantly. The 63% of consumers who currently trust AI recommendations represents a rapidly growing baseline—not a ceiling. Common Crawl's 3.4 billion-page archive shows that most e-commerce sites are already visible to some AI systems, but the quality of that visibility varies enormously based on technical setup.
Brands that fix JavaScript rendering and complete schema markup now are building a foundation that gets more valuable as AI adoption accelerates. The investment required—primarily engineering time and schema implementation—is modest compared to the cost of traditional SEO campaigns with equivalent reach.
---
## Next Steps: Building an AI Crawler Visibility Strategy
AI crawler optimization is not a one-time fix. Crawler behavior, content policies, and AI platform architectures evolve continuously—requiring quarterly audits to stay aligned. Here's how to build a sustainable strategy:
- **Conduct a baseline audit** across all three layers using the checklist above
- **Decide robots.txt policies deliberately**—allow, block, or selective access for each major AI crawler user-agent
- **Prioritize renderability fixes** for high-traffic product pages: SSR or SSG implementation for CSR-heavy pages
- **Complete and validate schema markup** on all product detail pages, starting with Product, Offer, and AggregateRating
- **Monitor AI crawler activity** in server logs and track AI-generated product mentions and recommendations over time
- **Integrate AI crawler optimization** into ongoing technical SEO and accessibility workflows—not as a separate initiative
Involving both technical teams (engineering) and business stakeholders (product, marketing) in robots.txt and content strategy decisions is essential. These are business decisions with commercial consequences, not just developer tickets. Accessibility improvements and AI optimization reinforce each other at every layer—semantic HTML, descriptive alt text, and logical page structure serve both audiences simultaneously.
Looking ahead, the brands that move first on AI crawler visibility will establish recommendations in AI systems before the channel becomes competitive. Competitors are still fighting for Google rankings. Early movers can become visible to the AI assistants customers are already using.
**Ready to build an AI crawler visibility strategy? [Schedule a 30-minute consultation with technical strategy specialists](https://calendly.com/ramon-joinhexagon/30min) to discuss specific setup and get a prioritized roadmap for AI optimization.**H
Hexagon Team
Published July 1, 2026