trainingbrandbrands
The AI Training Data Gap: Why Your E-Commerce Brand Is Invisible to ChatGPT (And How to Fix It)
Over 70% of consumers using AI assistants for product research never run a traditional search query. If your brand isn't represented in AI training data, you're missing the new front door to e-commerce discovery—and most brands don't even know it.
14 min read

---
# The AI Training Data Gap: Why Your E-Commerce Brand Is Invisible to ChatGPT (And How to Fix It)
*Over 70% of consumers using AI assistants for product research never run a traditional search query. If a brand isn't in ChatGPT's training data, it's missing the new front door to e-commerce—and most brands don't even know it's closing.*
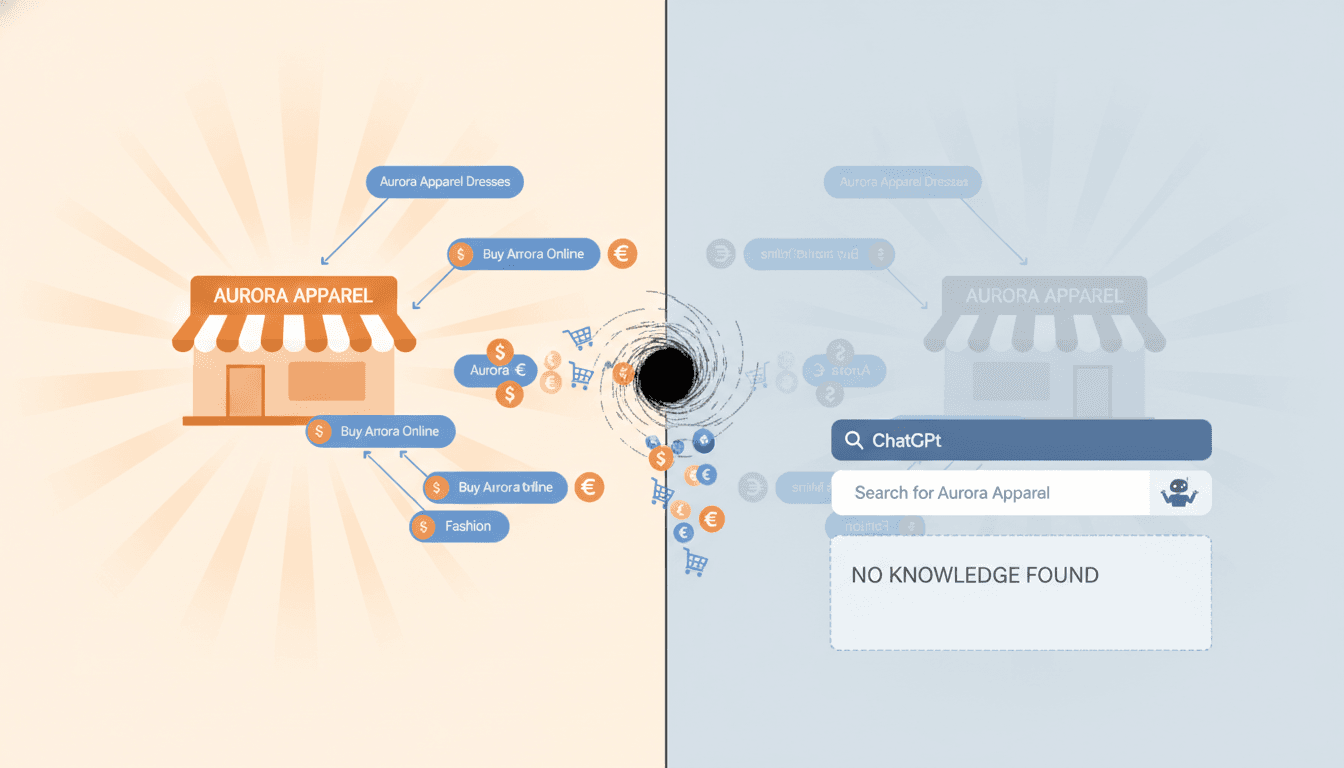
[IMG: Split-screen visual showing a consumer asking ChatGPT for product recommendations on one side, and an e-commerce brand's website with zero AI-driven traffic on the other]
## The New Visibility Crisis
Over 70% of consumers who use AI assistants for product research skip Google entirely. They ask ChatGPT, Claude, or Perplexity directly—and these AI models have become a primary discovery channel for e-commerce. But here's the problem: if a brand launched in the last 12–24 months, or if it's a smaller player without significant press coverage, ChatGPT doesn't know it exists.
Not because the products aren't good. Not because the marketing is weak. But because of a structural gap in how AI models are trained—one that creates a predictable, measurable, and fixable visibility problem.
This guide explains why it happens, and exactly what brands can do about it.
---
## The AI Training Data Gap: A New Visibility Problem
Every major large language model operates on a fundamental constraint: it learns from a frozen snapshot of the internet, captured at a specific date called the **training cutoff**. GPT-4o was trained on data through October 2023. Claude 3.5 Sonnet's cutoff is April 2024. Gemini and Perplexity operate on similar timelines. That means the AI customers are talking to right now is working from a picture of the world that is, at minimum, 12–18 months old.
The lag compounds further. Between a model's training cutoff and its public release, another 6–12 months typically pass. Then the model remains in active use for 1–3 years post-release. The result: a brand could be invisible to the dominant AI assistant for **2–4 years** from the moment its training data snapshot was collected.
For e-commerce, that window is commercially devastating.
The numbers tell the story. Approximately [500,000–600,000 new e-commerce businesses launch in the United States each year](https://www.census.gov/econ/bfs/index.html), according to U.S. Census Bureau Business Formation Statistics. Given the 12–24 month lag baked into every major LLM, hundreds of thousands of legitimate brands are structurally excluded from AI training data at any given time—not due to quality, but due to timing alone.
The stakes are enormous. ChatGPT alone processes over [10 million product and brand recommendation queries per day](https://www.reuters.com/technology/chatgpt-sets-record-fastest-growing-user-base-analyst-note-2023-02-01/). Generative AI search is projected to influence [$200 billion in U.S. e-commerce revenue by 2027](https://www.gartner.com/en/documents/4227099), according to Gartner. This is not a technical curiosity—it is a front-of-funnel revenue problem.
---
## How LLM Training Cutoffs Create Structural Invisibility
LLM training is a snapshot process, not continuous learning. When a model like GPT-4 or Claude is trained, developers feed it billions of web pages, articles, forum posts, and structured data collected up to a specific date. After training completes, the model's knowledge is frozen.
It cannot discover new brands, new product launches, or new market developments on its own. This creates what researchers call **recency bias inversion**: newer brands are systematically disadvantaged despite being fresher and potentially more relevant. Older, more frequently cited brands receive disproportionately more weight in AI outputs because they appear across more documents, time periods, and contexts in the training corpus—reinforcing incumbent brand advantage, as noted in [MIT Technology Review's research on AI recommendation systems](https://www.technologyreview.com).
Brands founded after a model's training cutoff simply don't exist in the model's probabilistic map of the world.
However, not all AI discovery works the same way. The distinction between base LLMs and retrieval-augmented generation (RAG) models matters significantly. Base LLMs like ChatGPT (in default mode) and Claude rely entirely on training data to generate responses. RAG-based platforms like Perplexity AI combine a base LLM with real-time web retrieval, giving brands with strong current SEO a pathway to visibility even without deep training data representation.
The catch: ChatGPT's browsing mode defaults to base training for most brand recommendation queries unless the user explicitly prompts a web search. The majority of AI-driven brand discovery still relies on static training data. This means the structural disadvantage is real and immediate.
The problem compounds for smaller brands. Only [15–20% of e-commerce brands with annual revenues under $10M](https://www.brightedge.com/resources/research-reports) have sufficient third-party digital footprint—press coverage, reviews, forum mentions—to be reliably recognized by leading LLMs, according to BrightEdge. Smaller brands lack the PR budgets to build third-party presence quickly.
The [Common Crawl dataset](https://commoncrawl.org/)—one of the largest training data sources for most major LLMs—prioritizes high-authority domains, meaning low-DA e-commerce sites are systematically underrepresented or entirely absent.
---
## Why External Signals Matter More Than Self-Published Content
Here's how LLMs decide what they know about a brand: they weight corroborated external signals far more heavily than self-published content. A brand's own website, blog, and social media profiles carry relatively little authority in training data pipelines. What matters is whether *other* authoritative sources—press outlets, review platforms, forums, and encyclopedic references—have documented and validated the brand's existence.
According to Ethan Mollick, Associate Professor at the Wharton School of Business: "LLMs are essentially a compressed, probabilistic snapshot of the internet at a specific point in time. The brands that have the richest, most corroborated presence in that snapshot—across news sites, forums, reviews, and editorial content—are the ones the model will confidently recommend."
The **training data authority hierarchy** works roughly as follows, from highest to lowest weight:
- **Wikipedia entries** — Brands with Wikipedia pages are cited in AI-generated recommendations at a rate [3–5x higher](https://www.semrush.com/blog/ai-visibility/) than comparable brands without Wikipedia presence, according to Similarweb and SEMrush AI Visibility Research
- **Editorial press coverage** — Coverage in recognized publications signals legitimacy and authority to training pipelines
- **Third-party review platforms** — Trustpilot, G2, and Capterra aggregations are frequently indexed and cited
- **Community mentions** — Reddit threads, industry forums, and niche community discussions carry significant weight
- **Structured data (schema markup)** — JSON-LD and schema markup help LLMs and RAG systems index and retrieve information accurately
Self-published content alone is insufficient for AI visibility. Amanda Natividad, VP of Marketing at SparkToro, frames it precisely: "The training data cutoff problem is real, but it's only half the story. The other half is that even brands that existed before the cutoff are invisible if they didn't have a sufficient third-party footprint."
AI doesn't reward existence—it rewards documented, corroborated existence.
---
## Diagnosing Brand AI Visibility: A Practical Framework
Before building an AI visibility strategy, brands need to understand where they currently stand. This diagnostic takes 15 minutes and provides immediate insight into competitive position.
**Step 1: Test category-level recognition.** Open ChatGPT, Claude, Perplexity, and Gemini separately and ask: *"What are the best [product category] brands for [target customer]?"* Note whether the brand appears, and if so, how it's described. Do competitors appear? Does the AI seem confident in its recommendations?
**Step 2: Test brand-level recognition.** Ask directly: *"Tell me about [Brand Name]. What do they sell, who are they for, and what do customers say about them?"* Look for accuracy, detail, and whether the AI cites specific products or customer sentiment. Vague or generic responses indicate weak training data representation.
**Step 3: Test comparison visibility.** Ask: *"Compare [Brand Name] with [Competitor A] and [Competitor B]."* This reveals whether the AI can represent the brand accurately in a competitive context—a high-stakes scenario for purchase decisions.
Watch for these **red flags** in AI responses:
- The AI states it has no information about the brand
- The AI confuses the brand with a competitor or similar-sounding company
- The AI describes outdated products, incorrect pricing, or missing product lines
- The AI provides generic filler content instead of specific brand details
- The brand is absent from category-level recommendation lists where competitors appear
Brands that are misrepresented face a particularly damaging outcome: LLMs that hallucinate brand details can actively mislead potential customers. Rand Fishkin, Co-founder and CEO of SparkToro, notes: "The brands that will win in the AI era are not necessarily the ones with the best products—they're the ones whose information is most thoroughly embedded in the data ecosystems that AI systems learn from."
If a brand isn't in the training data, it doesn't exist to the model.
---
**Ready to Fix Your AI Visibility Gap?**
Not sure if a brand is recognized by ChatGPT, Claude, and Perplexity? Or unsure where to start building third-party authority?
Book a free 30-minute AI Visibility Diagnostic. The team will:
- Test the brand across major LLMs and RAG platforms
- Identify specific visibility gaps
- Create a prioritized roadmap for improving AI discoverability
[**Book Your Free Diagnostic →**](https://calendly.com/ramon-joinhexagon/30min)
---
## The Third-Party Authority Imperative: Building an AI-Visible Footprint
Third-party presence is the single most important lever for AI visibility—and it works for both current RAG-based discovery and future LLM training cycles. Building a diverse, authoritative external footprint is not a short-term tactic; it is a compounding strategic asset that will pay dividends across multiple discovery channels for years to come.
Here's how to approach it by priority tier.
**High-Impact Actions (Start Immediately)**
- **Pursue earned press coverage** in industry publications, niche trade outlets, and regional business media. Earned media is heavily weighted in LLM training pipelines and signals authority to both crawlers and training data curators.
- **Claim and optimize review platform profiles** on Trustpilot, G2, and Capterra. These platforms are indexed quickly by RAG systems and carry significant weight in training datasets.
- **Build a Wikipedia presence** where warranted. Wikipedia is one of the most heavily weighted sources in LLM training datasets—brands cited there appear in AI recommendations at 3–5x the rate of comparable brands without Wikipedia entries.
**Medium-Impact Actions (Weeks 4–12)**
- **Engage authentically in community spaces** — Reddit, industry forums, and niche communities create discoverable third-party mentions that training pipelines capture and weight.
- **Implement structured data (JSON-LD schema)** across product pages, brand pages, and review aggregations. Structured data helps both RAG systems and future training pipelines index and retrieve brand information accurately.
- **Pursue guest editorial placements** in recognized publications to build corroborated brand mentions across diverse, high-authority domains.
**Long-Term Foundation (Ongoing)**
- Develop a consistent cadence of newsworthy announcements—product launches, partnerships, milestones—to generate recurring press coverage that accumulates in training datasets over time.
- Build relationships with industry analysts and journalists who cover the category, as editorial mentions in recognized outlets carry outsized weight in training pipelines.
[IMG: Pyramid diagram showing the training data authority hierarchy: Wikipedia at top, then editorial press, review platforms, community mentions, and structured data at the base]
---
## Strategies for Brands with Post-Cutoff Founding Dates
Brands founded after major LLM training cutoffs face a double disadvantage: no training data representation *and* no established third-party presence yet. The structural challenge is real, but it is not insurmountable. The key is sequencing the right tactics for the right platforms.
**Prioritize RAG-based platforms first.** Perplexity AI uses a hybrid model combining a base LLM with real-time web retrieval, meaning brands with strong current SEO and structured content have a pathway to AI visibility even without deep training data representation. A brand that launched in mid-2024 may be invisible to ChatGPT's base model but fully discoverable on Perplexity if its product pages are well-structured and indexed.
Here's how to accelerate third-party content creation for post-cutoff brands:
- **Distribute press releases to industry outlets** — Newswire distribution to niche trade publications generates indexed, third-party content quickly and signals brand legitimacy to RAG crawlers
- **List on review platforms immediately** — G2, Capterra, and Trustpilot profiles are indexed rapidly and serve as discoverable third-party signals for RAG systems
- **Engage on Reddit and relevant forums** — Authentic community participation creates brand mentions in high-authority, frequently crawled environments
- **Implement schema markup from day one** — Structured data ensures that when RAG systems do find the brand, they can accurately extract and present key information
Aleyda Solis, International SEO Consultant and Founder of Orainti, captures the urgency: "We're entering a world where the question isn't just 'can customers find you on Google?' but 'does the AI know you exist?' These are fundamentally different questions with fundamentally different answers, and most brands haven't woken up to that distinction yet."
Post-cutoff brands that begin building third-party presence now are positioning themselves for inclusion in the next major training cycle—a window that is closer than most marketers realize.
---
## The Long Game: Preparing for the Next LLM Training Cycle
Next major LLM training cycles are likely 12–24 months away, and the brands building third-party authority today are making a direct investment in future training data inclusion. LLM training pipelines do not select data randomly—they prioritize high-authority domains, frequently cited sources, and content that appears across multiple corroborating contexts.
Brands that have built diverse, high-quality third-party presence will be disproportionately represented in the next generation of AI models. Looking ahead, a 12–24 month roadmap for AI-visible presence looks like this:
- **Months 1–3:** Audit current third-party footprint; claim review platform profiles; implement structured data; identify press opportunities in trade and industry media
- **Months 3–6:** Execute first wave of earned media; build Wikipedia presence where eligible; engage in community spaces; begin accumulating verified reviews
- **Months 6–12:** Develop editorial relationships; pursue higher-authority press placements; expand structured data coverage; monitor AI recognition across platforms quarterly
- **Months 12–24:** Sustain press cadence; deepen community presence; assess AI recognition improvements; optimize based on diagnostic results
Measuring progress toward AI visibility goals requires running the diagnostic framework described earlier on a quarterly basis—tracking whether brand recognition improves, whether descriptions become more accurate, and whether the brand begins appearing in category-level recommendations. Early movers in AI visibility strategy will have significant competitive advantage, because the brands that build deep third-party authority now will be the ones that LLMs confidently recommend when the next training cycle captures the web.
[IMG: Timeline graphic showing the 12–24 month roadmap for building AI-visible brand presence, with milestones at months 3, 6, 12, and 24]
---
## Key Takeaways: An AI Visibility Action Plan
The core problem is structural: LLM training cutoffs create a 12–24 month lag that excludes hundreds of thousands of legitimate e-commerce brands from AI recommendations—not because of quality, but because of timing and third-party footprint. The solution is equally clear: build diverse, authoritative external presence that training pipelines and RAG systems can discover, index, and weight.
With generative AI search projected to influence $200 billion in U.S. e-commerce revenue by 2027, the commercial stakes of AI invisibility are escalating rapidly. For example, brands that act now—building the third-party authority that training pipelines reward—will enter the next LLM training cycle with a compounding advantage over competitors who are still waiting to see how AI search develops.
**Immediate actions (this month):**
- Run the diagnostic framework across ChatGPT, Claude, Perplexity, and Gemini
- Claim and optimize profiles on Trustpilot, G2, and Capterra
- Implement JSON-LD schema markup across key brand and product pages
**Short-term actions (months 1–6):**
- Pursue earned press coverage in industry and trade publications
- Build Wikipedia presence where the brand meets notability criteria
- Engage authentically in Reddit and industry forum communities
**Long-term actions (months 6–24):**
- Sustain a consistent press and editorial cadence
- Deepen review platform presence with verified customer reviews
- Run quarterly AI visibility diagnostics to track progress
AI-assisted product research already accounts for 70% of discovery in many categories. The window to build that presence before the next training snapshot closes is open now—but it won't stay open indefinitely.
---
**Ready to Fix Your AI Visibility Gap?**
Not sure if a brand is recognized by ChatGPT, Claude, and Perplexity? Or unsure where to start building third-party authority?
Book a free 30-minute AI Visibility Diagnostic. The team will:
- Test the brand across major LLMs and RAG platforms
- Identify specific visibility gaps
- Create a prioritized roadmap for improving AI discoverability
[**Book Your Free Diagnostic →**](https://calendly.com/ramon-joinhexagon/30min)H
Hexagon Team
Published June 7, 2026